[System Architecture] 인스타그램 시스템 아키텍쳐
정말 오랜만의 기술 블로깅이다. 100% 자의에 의한 블로깅은 아니지만, 작년에 워낙 이런저런 일들로 바빴었는데 이렇게라도 블로깅을 할 수 있게되어 뿌듯하다. 이번 주제는 너무 무겁지도 않지만 그렇다고 너무 가볍지만은 않은 주제로 선정했다. 더불어 개인적으로도 도움이 될 수 있는 주제를 잡았다. 인스타그램은 설명이 더 필요 없는 서비스이다. 원래 서비스 목적과는 다르게 비공개 계정으로 개인 이미지 백업용으로 사용하고 있지만, 가끔 공개된 글들을 보고있으면 정말 많은 데이터들이 무한히 공급되는 것과 같이 보인다. 과연 이런 시스템은 어떻게 구성되고 있는 것일까?
Instagram 시스템 아키텍쳐
인스타그램 시스템 아키텍쳐의 가장 핵심은 어떻게 수십억개의 서비스로 수백만 QPS(Queries per second)를 제공하는지에 대한 부분이다. 데이터를 어떻게 저장하고 적절한 데이터를 찾아 각 유저에게 노출하는 것일까?
1. Backend 시스템은 어떻게 구성하고 잇을까?
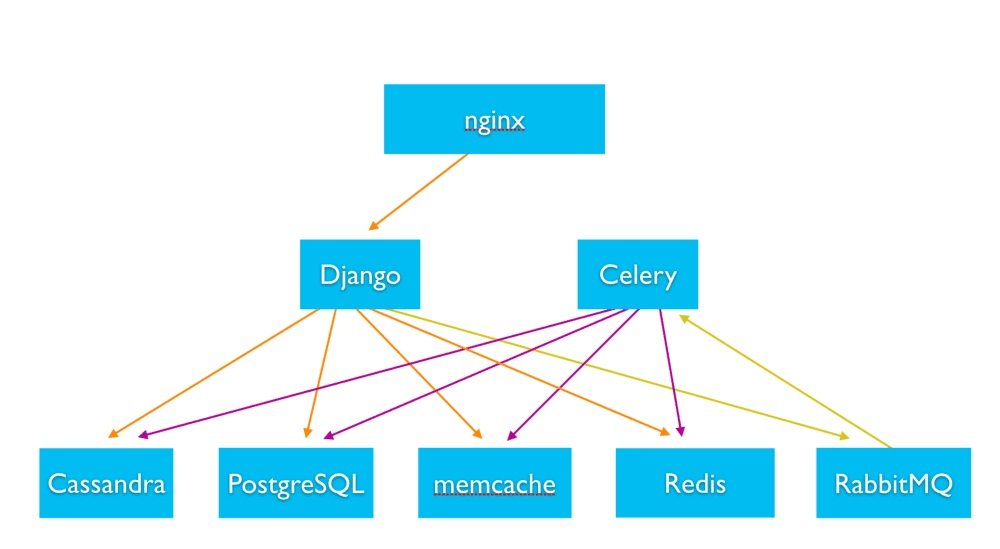
서버는 장고Django로 파이썬Django Python으로 구성되어 있다. 모든 웹과 비동기 서버들은 분산환경으로 stateless형태로 서비스 되고 있다.
Backend architecture
https://scaleyourapp.com/wp-content/uploads/2019/05/Instagram-architecture-min-jpeg.jpg
{kind=link}
백엔드 시스템은 각 유저에게 개인화된 콘텐츠를 제공하기 위해서 다양한 데이터 스토리지를 사용하고 있다. (Cassandra, PostgreSQL, Memcache, and Redis)
비동기 프로세스 Asynchronous Behavior
RabbitMQ와 Celerys는 비동기 태스크를 처리하기 위해서 사용되는데 고객에게 notification을 제공하거나 다른 시스템 백그라운드를 처리하기 위함이다.
Celery는 비동키 작업 큐로 분산 메세지 통신을 기반으로 하고있으며 실시간 처리에 중점을 두고 있다. 스케쥴링도 제공하고 있다. 셀러리를 위한 메세지 브로커로는 rabbitMQ이다
RabbitMQ는 널리 사용되는 오픈 소스 메세지 브로커로 AMQP Advanced Messaging Queuing Protocol을 사용한다. d Messaging Queuing Protocol.
Gearman은 시스템 내에 여러노드들 간에 분산 처리를 하기 위해 사용되고, 이것은 비동기 처리 예를들어 사진/영상 업로드와 같은 작업들에 사용된다. 이것은 다른 프로세스/노드간와의 분산 처리를 위한 프레임워크distributing tasks to other machines or processes로 이러한 작업들을 수행하는데 유용하다. 이 프레임워크 안에는 고가용성 웹사이트 부터 데이터베이스 백업 이벤트 전송까지 전반적인 어플리케이션을 가지고 있다.
**플랫폼에서 트렌딩 해쉬태그 처리하기 **
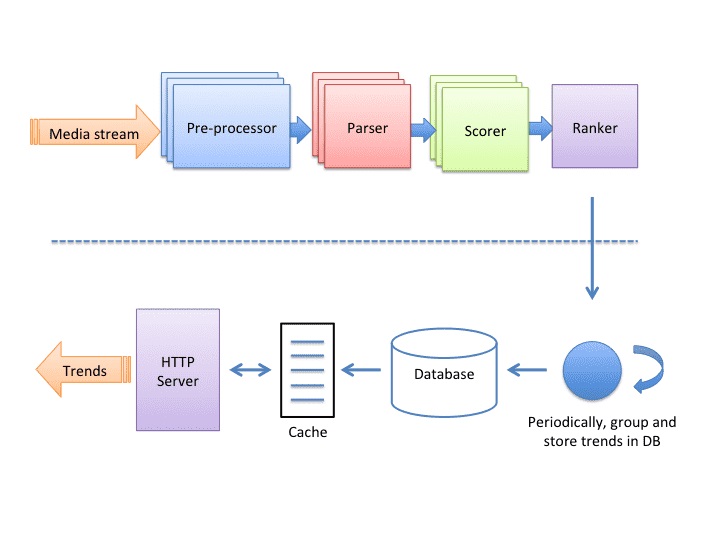
트렌딩 시스템은 stream processing 어플리케이션으로 4개의 컴포넌트가 리니어하게 연결되어 있다. https://scaleyourapp.com/wp-content/uploads/2019/05/Instagram-architecture-jpeg.jpg
{kind=link}
노드들의 역할은 이벤트 로그의 스트림을 컨슘해서 트렌드 콘텐츠에 대한 랭킹 리스트를 생성하게 된다. 그 결과 해쉬태그 또는 장소에대한 트렌드 순위가 나오게 된다.
전처리 노드Pre-processor Node The pre-processor node attaches the necessary data needed to apply filters on the original media that has metadata attached to it 전처리노드는 오리지널 미디어에 필터 적용을 위해 필요한 메타데이터를 추가하는것이다.
파서 노드Parser Node The parser node extracts all the hashtags attached to an image and applies filters to it. 파서노드는 이미지에 붙어있는 해쉬태그나 필터를 추출한다.
스코어 노드Scorer Node The scorer node keeps track of the counters for each hashtag based on time. All the counter data is kept in the cache, also persisted for durability. 스코어 노드는 시간 기준으로 각 해쉬테그의 카운터를 추적한다. 모든 카운터 데이터는 캐쉬에 저장되고 지속성durability를 위해서 persisted 된다.
랭커노드Ranker Node The role of the ranker node is to compute the trending scores of hashtags. The trends are served from a read-through cache that is Memcache and the database is Postgres. 랭커노드의 역할은 해시태그의 트렌드 점수를 계산하는 것이다. 이러한 트렌드는 read-through 캐시부터 서빙되는데 그 역할을 하는 것이 memcache와 postgres 데이터베이스 사용했다.
Databases Used @Instagram
PostgreSQL is the primary database of the application, it stores most of the data of the platform such as user data, photos, tags, meta-tags, etc. PostgreSQL은 주요 database로 사용되며 대부분의 데이터를 저장하고 있다. 사용자 데이터, 사진, 태그, 메타 태그 등등
As the platform gained popularity and the data grew huge over time, the engineering team at Insta meditated on different NoSQL solutions to scale and finally decided to shard the existing PostgreSQL database as it best suited their requirements. 서비스의 데이터가 기하급수적으로 증가함에 따라 엔지니어링 팀은 NoSQL 솔루션을 고려했었고 결국에 기존의 PostgreSQL 데이터베이스를 샤딩하기로 결정했고 그것이 그들의 요구사항에 최적이었다. 샤딩에 대해서 더 확인하기 위해서는 https://scaleyourapp.com/youtube-database-how-does-it-store-so-many-videos-without-running-out-of-storage-space/ 를 참고
Hive is used for data archiving. It’s a data warehousing software built on top of Apache Hadoop for data query and analytics capabilities. A scheduled batch process runs at regular intervals to archive data from PostgreSQL DB to Hive. Instagram의 기본 데이터베이스 클러스터에는 서로 다른 영역에 12개의 복제본이 포함되어 있으며 12개의 Quadruple 초대형 메모리 인스턴스가 포함한다. 하이브https://hive.apache.org/는 데이터 아카이빙을 위해서 사용된다. 그것의 데이터 웨어하우징 소프트웨어는 하둡위에서 쿼리하고 분석할 수 있게 만들어졌다. 스케쥴된 배치는 주기적으로 PostgreSQL DB에서 Hive로 데이터 아카이빙을 한다.
Vmtouchhttps://hoytech.com/vmtouch/, a tool for learning about and managing the file system cache of Unix and Unix-like servers, is used to manage in-memory data when moving from one machine to another. Vmtouch는 Unix 및 Unix 계열 서버의 파일 시스템 캐시를 관리하기 위한 도구로 한 시스템에서 다른 시스템으로 이동할 때 메모리 내 데이터를 관리하는 데 사용됩니다.
Using Pgbouncerhttps://pgbouncer.github.io/ to pool PostgreSQL connections when connecting with the backend web server resulted in a huge performance boost. 백엔드 웹서버에 연결할 때 Pgbouncer 사용하여 PostgreSQL 커넥션 풀을 이용하면 큰 성능 향상이 있다.
Redis an in-memory database is used to store the activity feed, sessions and other app’s real-time data. 레디스https://redis.io/는 인메모리 디비로 활동 피드, 세션 그리고 다른 앱의 실시간 데이터를 저장하는데 사용된다.
Memcachehttps://memcached.org/ an open-source distributed memory caching system is used for caching throughout the service. 멤캐시는 분산 메모리 캐싱 시스템으로 서비스들의 캐시로 사용하기 위해 사용한다.
클러스터 내의 데이터 관리Data Management in the Cluster
Data across the cluster is eventually consistent, cache tiers are co-located with the web servers in the same data center to avoid latency. 클러스터 간 데이터 처리는 결국 일관성을 갖게 되고, 캐시레이어는 웹서버와 동일한 데이터 센터에 위치되어 레이턴시를 최소화 했다.
The data is classified into global and local data which helps the team to scale. Global data is replicated across different data centers across geographical zones. On the other hand, the local data is confined to specific data centers. 데이터는 글로벌 데이터와 로컬 데이터를 나눠서 스케일 하기 좋도록 하였다. 글로벌 데이터는 여러 지역에 걸처 다른 데이터센터에 복제가 되어 있다. 반면에 로컬 데이터는 특정 데이터 센터와 연관이 있다.
Initially, the backend of the app was hosted on AWS but was later migrated to Facebook data centers. This eased the integration of Instagram with other Facebook services, cut down latency and enabled them to leverage the frameworks, tools for large-scale deployments built by the Facebook engineering team. 초기에 백엔드 앱은 AWS에 호스팅 되어 있었으나 나중에 facebook데이터에 마이그레이션 된다. 이를 통해 Instagram과 다른 Facebook 서비스의 통합이 쉬워지고 대기 시간이 줄어들며 Facebook 엔지니어링 팀이 구축한 대규모 배포용 도구인 프레임워크를 활용할 수 있게 되었습니다. https://instagram-engineering.com/migrating-from-aws-to-fb-86b16f6766e2
Instagram’s backend code is powered by #Django #Python. #PostgreSQL is the primary #database of the application. Learn more here #distributedsystems #softwarearchitecture
Monitoring
With so many instances powering the service, monitoring plays a key role in ensuring the health and availability of the service.서비스에 참여하는 인스턴스가 너무 많기 때문에 모니터링은 서비스의 상태와 가용성을 보장하는 데 중요한 역할을 합니다.
Muninhttp://munin-monitoring.org/ is an open-source resource, network and infrastructure monitoring tool used by Instagram to track metrics across the service and get notified of any anomalies.Munin은 Instagram에서 서비스 전체의 지표를 추적하고 이상 징후에 대한 알림을 받는 데 사용하는 오픈 소스 리소스, 네트워크 및 인프라 모니터링 도구입니다.
StatsD a network daemon is used to track statistics like counters and timers. Counters at Instagram are used to track events like user signups, number of likes, etc. Timers are used to time the generation of feeds and other events that are performed by users on the app. These statistics are almost real-time and enable the developers to evaluate the system and code changes immediately .StatsDhttps://github.com/statsd/statsd 네트워크 데몬은 카운터 및 타이머와 같은 통계를 추적하는 데 사용됩니다. Instagram의 카운터는 사용자 가입, 좋아요 수 등과 같은 이벤트를 추적하는 데 사용됩니다. 타이머는 앱에서 사용자가 수행하는 피드 및 기타 이벤트 생성 시간을 측정하는 데 사용됩니다. 이러한 통계는 거의 실시간이며 개발자가 시스템 및 코드 변경 사항을 즉시 평가할 수 있습니다.
Dogslow a Django middleware is used to watch the running processes and a snapshot is taken of any process taking longer than the stipulated time by the middleware and the file is written to the disk.Dogslow Django 미들웨어는 실행 중인 프로세스를 감시하는 데 사용되며 미들웨어에서 규정된 시간보다 오래 걸리는 프로세스의 스냅샷을 찍어 파일을 디스크에 씁니다.
Pingdom is used for the website’s external monitoring, ensuring expected performance and availability. PagerDuty is used for notifications & incident response.Pingdom은 웹사이트의 외부 모니터링에 사용되어 예상 성능과 가용성을 보장합니다. PagerDuty는 알림 및 사고 대응에 사용됩니다.
**How Does Instagram Runs A Search For Content Through Billions of Images? **
Instagram initially used Elasticsearch for its search feature but later migrated to Unicorn, a social graph-aware search engine built by Facebook in-house. Instagram은 처음에 검색 기능을 위해 Elasticsearch를 사용했지만 나중에 Facebook이 사내에서 구축한 소셜 그래프 인식 검색 엔진인 Unicorn으로 마이그레이션했습니다.https://research.facebook.com/publications/unicorn-a-system-for-searching-the-social-graph/
Unicorn powers search at Facebook and has scaled to indexes containing trillions of documents. It allows the application to save locations, users, hashtags, etc and the relationship between these entities. Unicorn은 Facebook에서 검색 기능을 강화하고 수조 개의 문서를 포함하는 인덱스로 확장되었습니다. 응용 프로그램이 위치, 사용자, 해시태그 등 및 이러한 엔터티 간의 관계를 저장할 수 있습니다.
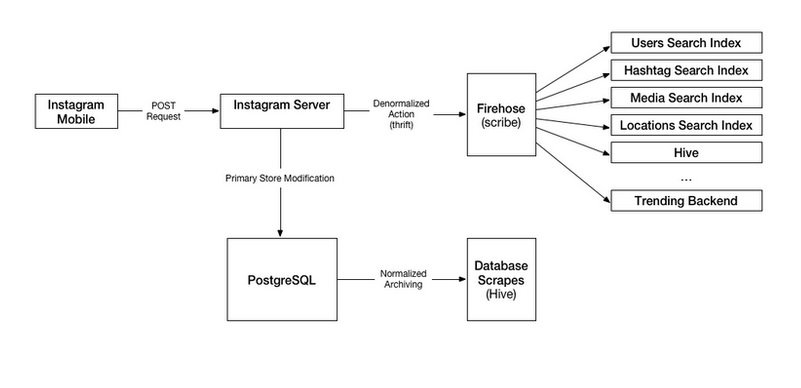
Speaking of Insta’s search infrastructure, it has denormalized data stores for users, locations, hashtags, media, etc. Insta의 검색 인프라에 대해 말하면 사용자, 위치, 해시태그, 미디어 등에 대한 데이터 저장소를 비정규화했습니다.
These data stores can also be called documents, which are grouped into sets to be processed by efficient set operations such as AND-OR and NOT. 이러한 데이터 저장소는 AND-OR 및 NOT과 같은 효율적인 집합 연산에 의해 처리되는 집합으로 그룹화된 문서라고도 합니다.
The search infrastructure has a system called Slipstream which breaks the user uploaded data, streams it through a Firehose and adds it to the search indexes. 검색 인프라에는 사용자가 업로드한 데이터를 깨고 Firehose를 통해 스트리밍하여 검색 인덱스에 추가하는 Slipstream이라는 시스템이 있습니다.
The data stored by these search indexes is more search-oriented as opposed to the regular persistence of uploaded data to PostgreSQL DB. 이러한 검색 인덱스에 의해 저장되는 데이터는 PostgreSQL DB에 업로드된 데이터의 일반적인 지속성과는 반대로 검색 지향적입니다.
Below is the search architecture diagram
https://scaleyourapp.com/wp-content/uploads/2019/05/Instagram-search-architecture-min-jpeg.jpg
{kind=link}
Image source: Instagram
References: Instagram search architecture Trending on Instagram Sharding at Instagram
reference.
https://scaleyourapp.com/instagram-architecture-how-does-it-store-search-billions-of-images/ https://instagram-engineering.com/under-the-hood-instagram-in-2015-8e8aff5ab7c2 https://www.enjoyalgorithms.com/blog/design-instagram https://medium.com/@alicrawford/instagram-the-principles-of-information-architecture-ia-used-to-support-user-experience-and-9e28ebf194d