[ADsP]1.통계분석의 시작
😃
이상한 순서이지만, 3장의 ‘데이터 분석’ 을 먼저 보려고 한다. 그 이유는 1장의 ‘데이터의 이해’ 부터 보게된다면 뒤로 갈 수록 쳐질것 같은 기분이 들어서이다. 두렵고 어려울 것이라 생각되는 부분을 가장 먼저 부수고 들어가보자!!
내용
일반적으로 데이터를 처리할 때 legacy시스템에서 직접 데이터를 가져오기도 하지만 ODS(Operational Data Store) 에서 데이터를 가져오는 것을 권고한다. 그 이유는 운영 중에 legacy시스템에서 데이터를 직접 가져오는 것은 legacy시스템에 부하를 유발함으로 운영 서비스에 영향을 끼칠 수 있기 때문이다. 따라서 Legacy에서 ODS로 데이터를 적재하는데 이때 데이터 변환이 필요하다면 별도의 staging 영역을 활용한다. 일반적으로 비정형 데이터는 RDB에 임시 저장후 텍스트 마이닝을 거쳐 데이터 마트(DM)과 결합시킨다. 또 소셜데이터 같은 경우 RDB에 심시 저장 후 사회 신경망 분석을 통한 결과를 DM과 결합한다. 이렇게 [ legacy -> staging -> ODS -> DW->DM]로 데이터가 적재되어사용된다. 분석은 각 단계에서 수행되어 각 단계의 데이터와 결합할 수 있다.
많은 분석 작업들이 ‘탐색적 자료 분석(EDA)‘를 통해 이루어지는데, 다양한 차원(dimension)과 값을 조합하여 특이점이나 규칙들 찾아낸다. 이때 시각화를 반드시 사용해야 하며 이를 통해 빠르게 특이점을 찾아낼 수 있다. 그 외에도 공간적 차원과 관련된 속성을 분석할 때에도 시각화 분석이 필요하다.
(ref.Introduction to scikit-learn – O’Reilly)
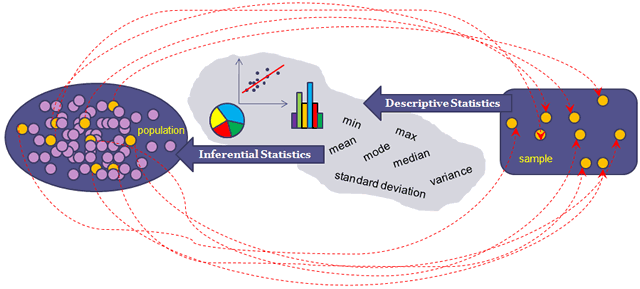
일반적으로 데이터 분석은 통계분석을 의미한다. 통계분석은 기술통계(descriptive statistics) 와 추측통계(infererential statistics) 로 나뉜다. 기술통계는 모집단으로부터 샘플링 하여 정보를 쉽게 숫자/그래프로 나타낸 것을 의미하고, 추측통계는 기술통계의 결과인 샘플 특정 모수에 관해 통계적으로 추론하는 것이다. 다시 이야기 하면 기술통계는 ‘각 연령 별 여당 후보의 지지율 분포’와 같은 샘플 데이터 자체를 표현 하는 것이고, 추측통계는 기술통계로부터 얻은 샘플링 결과를 일반화 시키고 그것을 통해 ‘여당 후보의 당선 가능성이 더 높다’라고 하는 것이다. 실제로 추측의 근거는 오직 샘플링 결과에 의존한 것이기 때문에 잘못되었을 수도 있다. 따라서 기술 통계 시 올바른 샘플링이 중요하다.
데이터 마이닝(Data Mining) 은 대용량 자료를 통해 관계,패턴,규칙을 찾고 모델로 만들어 기존에 알려지지 않은 유용한 지식을 추출하는 분석방법이다. 크게 기계학습(ML), 패턴인식(pattern recognition), DB내 지식탐색으로 나눌 수 있다. ML은 또 다시 인공신경망, 의사결정나무, 클러스터링, 베이지안 분류, SVM 등으로 세밀하게 나뉜다. 패턴인식은 사전지식과 패턴 데이터로 자료/패턴을 분류하는 방식이다. 가장 흔히 알고 있는 예가 기저귀 코너 옆 맥주진열과 같은 것이다. DB내 지식탐색은 전통적인 DW에서 DM을 구축하여 데이터를 확인하는것 이다.
또 복잡한 실제 상황을 단순화 시킨 컴퓨터 모델로 재현하는 것을 시뮬레이션 이라고 하고, 제약조건 하에서 목표값을 개선하는 방식을 최적화 라고 한다.
정리
- 데이터 처리 는 [(legacy)->staging->ODS->DW->DM] 으로 이루어진다.
- 시각화 는 낮은 수준의 분석이지만, 매우 효과적이고 EDA, 공간분석에서 필수이다.
- 공간분석 은 공간적 차원과 관련 속성을 시각화 하는 분석이다.
- EDA 는 탐색적 자료분석으로 다양한 차원과 값을 조합해가며 특이점을 찾는 것이다.
- 데이터마이닝 은 대용량자료로 부터 관계, 패턴, 규칙을 탐색하고 모형(모델)화 함으로써 유용한 지식을 추출하는 분석방법이다.
- 시뮬레이션 은 복잡한 실제상황을 단순화해 컴퓨터 모델로 만들어 재현하거나 변경하여 결과 예측하기 위한 방법이다.
- 최적화 는 제약조건하에서 목표값을 개선하는 방식으로 목적함수와 제약조건을 정의해 문제를 해결한다.
추가
-
데이터 마이닝의 판단 기준
- 정확도, 정밀도, 디텍트 레이트, 리프트
-
시뮬레이션의 판단 기준
- 처리량, 평균 대기 시간, 평균 큐 길이, 시스템 시간 등
-
비즈니스 영향도 평가(경영자 관점)
- 총소유비용(TCO),투자대비효과(ROI),순현재가치(NPV)